Network Architecture
Given a single image as input, FeatureNeRF adopts an encoder to extract the image feature , and then concatenate it with the query point as well as the view direction as the inputs for NeRF MLPs. Apart from density and color, we add two MLP branches to predict the feature vector and coordinate, which are supervised by two novel loss terms. Besides, we propose to extract internal NeRF feature as 3D-consistent feature representation.
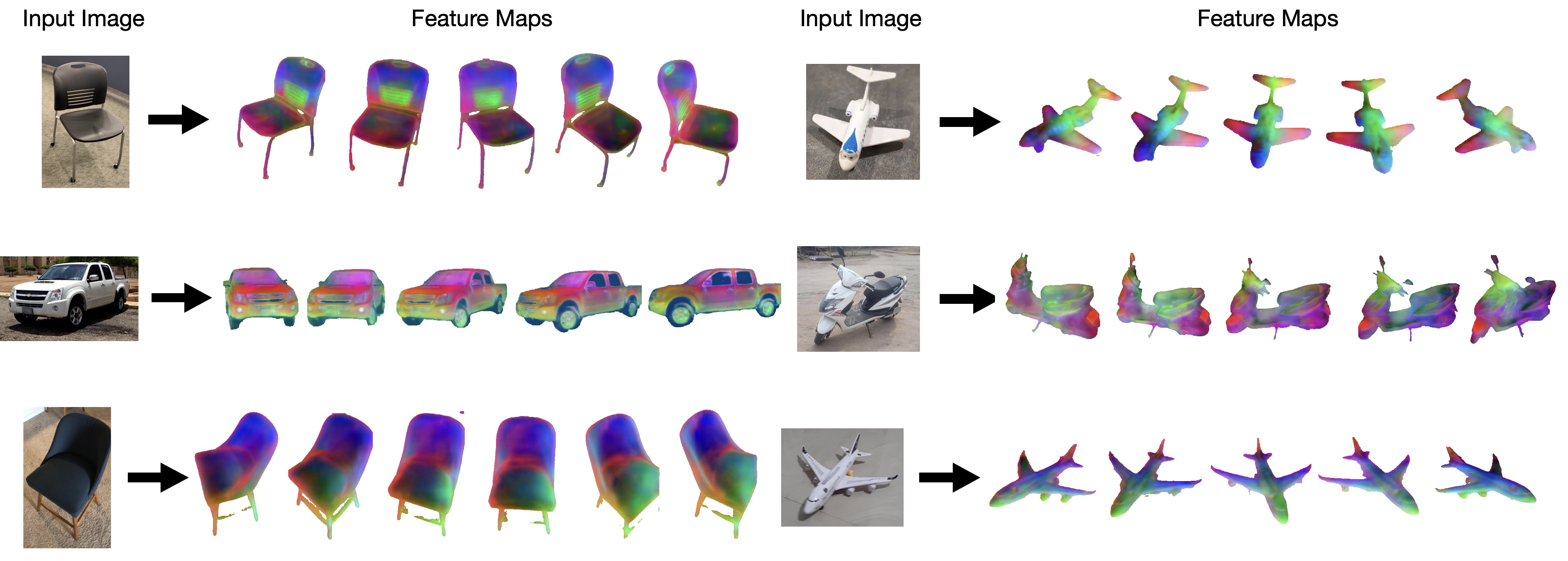
Novel-view Feature Maps
FeatureNeRF predict a 3D feature volume from a single image, and can be used to render novel-view feature maps.
Results
Keypoints Transfer
FeatureNeRF can also transfer semantic keypoints to both novel objects and novel views.

Part Co-segmentation
FeatureNeRF can also transfer part segmentation labels to novel objects or views in both 2D and 3D domain.