Network Architecture
Our generative model takes object point cloud and a sequence of joint positions as input and recovers corresponding robot hands. The proposed CGF takes the latent code z, object feature, and the query time t as inputs to predict the corresponding joint position.
Results
Simulation Results
Thanks to human demonstrations, our CGF generates more natural and reasonable trajectories which are helpful for the sim-to-real transfer.
More simulation results
Real-world Results
Our CGF successfully transfers the simulation trajectory to the real robot.
More real-world results
Test on Unseen Objects
Our CGF can generalize to unseen objects.
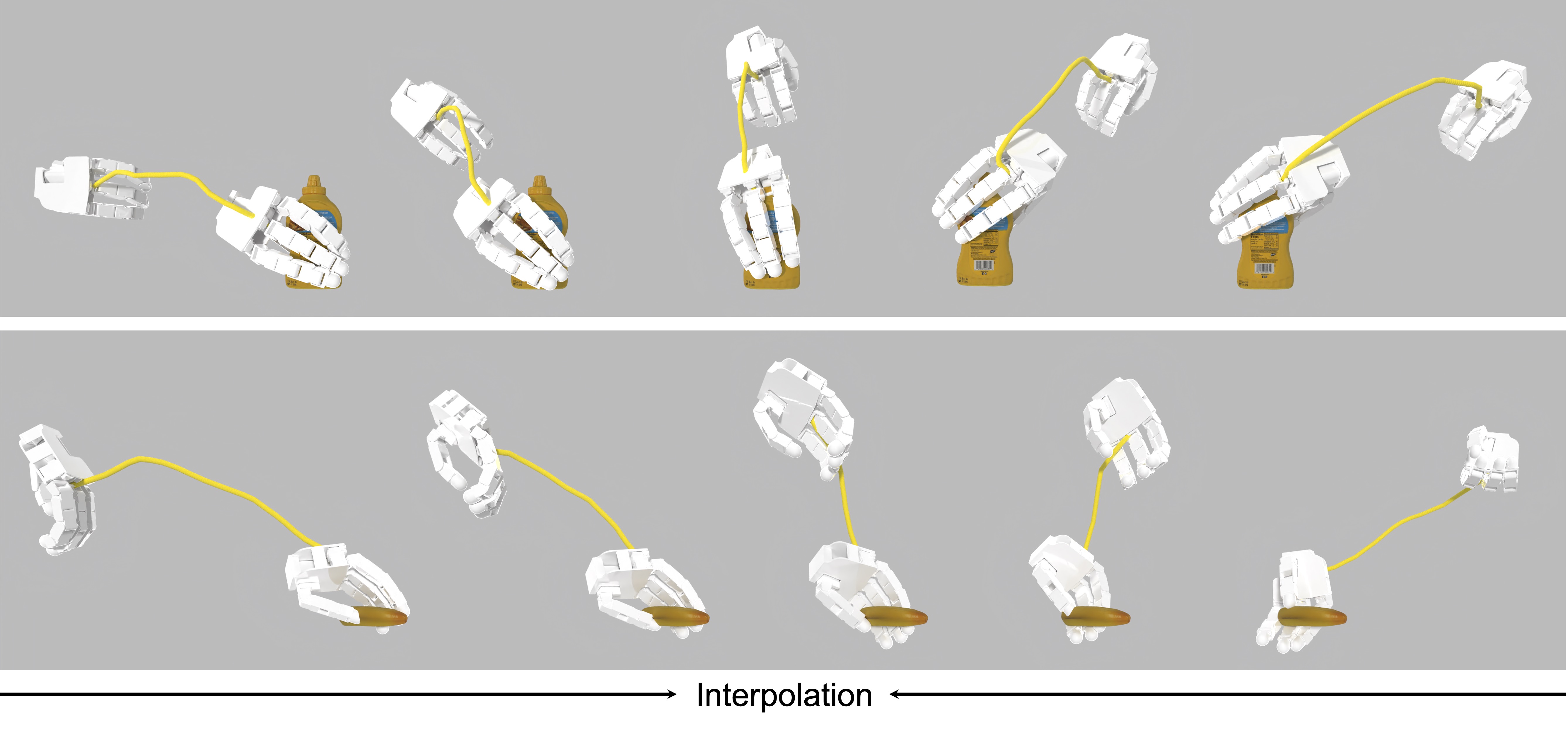
Interpolation Result
Our method produces diverse grasping and the interpolation between them are also plausible.